
SDDC Architecture - Mapping of Logical Components to Physical Location
Notice: This article is more than 9 years old. It might be outdated.
This article is part of a series of articles, focusing on the architecture of an SDDC via VMware Validated Designs.
Requirements
A Software Defined Data Center promises to be the new underpinning or platform for delivering today’s and tomorrow’s IT services. As such this next generation infrastructure needs to address some shortcomings of today’s infrastructure in order to be successful:
- Highly automated operation at Scale: Leaner organization that scales sub-linearly with an operating model build around automation. Leverage modular web-scale designs for unhampered scalability.
- Hardware and Software efficiencies: Support on-demand scaling for varying capacity needs. Improved resource pooling to drive increased utilization of resources and reduce cost.
- New and old business needs: Support legacy applications with traditional business continuity and disaster recovery, besides new cloud-native applications.
Logical Space
In this post we will map the physical space of the SDDC architecture to the logical space (See Figure 1).
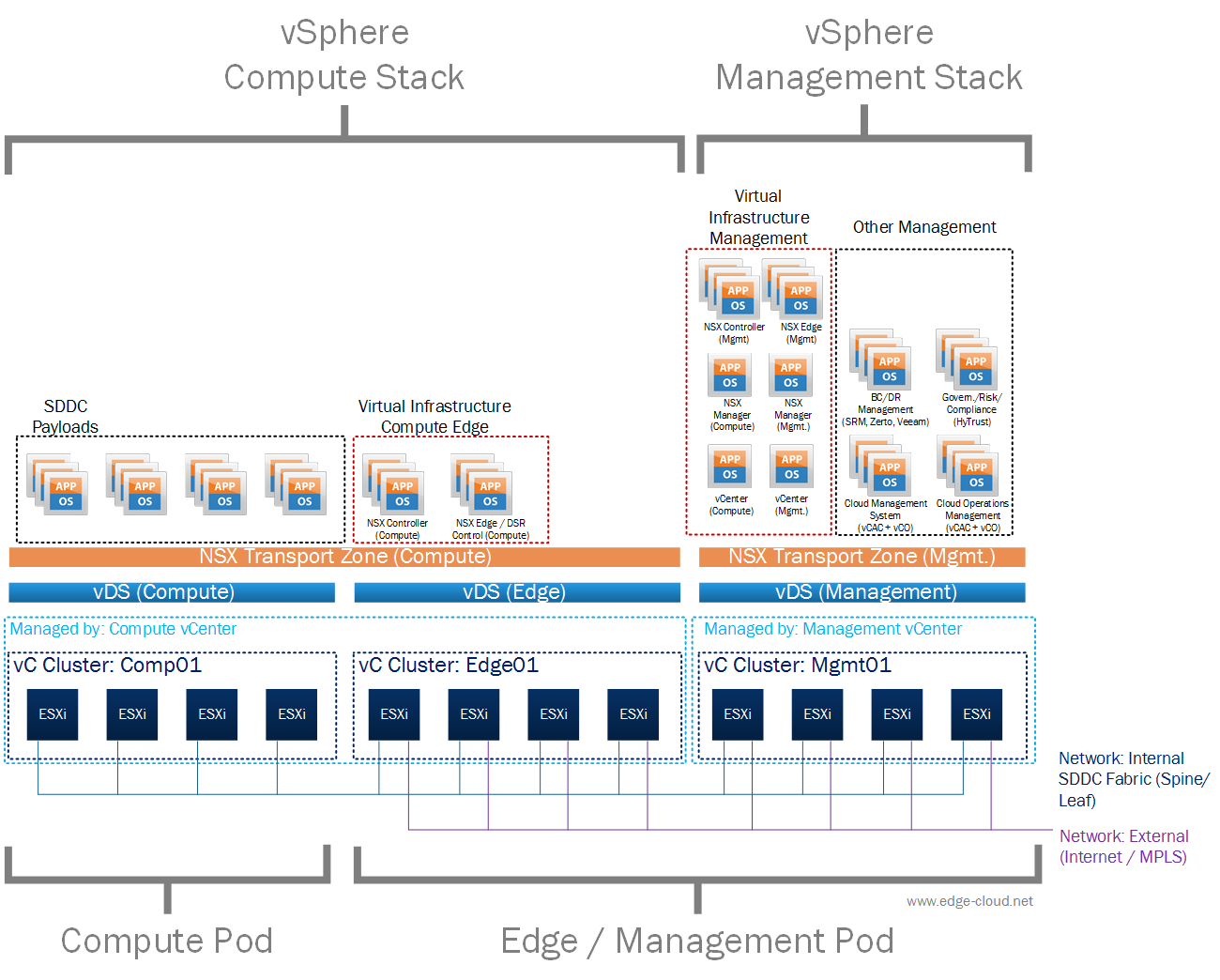
vSphere Clusters
For this we will start with the physical space that includes a Management POD, an Edge POD, and one or more Compute PODs. Each of these PODs maps to one cluster.
As a result we will end up with a single Management Cluster, one Edge cluster, and one or more Compute Clusters.
Here it is important to point out, that one Compute POD could house more than one Compute Cluster. This purely depends on the use case for this specific SDDC instance. In order to keep things simple and uniform it is recommended that in this case, the cluster size should be 1/4, 1/2, or 1/1 of the total available server count within a POD. This allows you to create multiple clusters in a uniform manner, without any waste. It is also important to point out, that a compute cluster cannot span more than one compute POD, as L2 host network traffic is not carried across PODs.
vSphere vCenter domains
The vSphere cluster above are distributed across two or more vCenters, which we will call stack. Each stack is therefore managed by one or more different vCenter and includes one or more vSphere cluster.
With that the Compute Stack includes:
- Compute cluster: Used to host workloads (also called payloads). These are tenant VMs that an operator of an SDDC could effectively charge for.
- Edge cluster: This vSphere cluster hosts the three NSX Controller VMs and NSX Provider Edge devices for the Compute Stack. NSX Provider Edges provide network connectivity between a physical VLAN based network and a VXLAN based overlay network.
The Management Stack includes:
-
Management cluster: The management stack houses two different set of virtual machines. Both sets are necessary for the operation of the SDDC itself.
- Virtual Infrastructure Management components: vSphere vCenter server, Platform Services Controller, NSX Managers, NSX Controller and NSX Edges for the Management stack. These components are part of the Virtual Infrastructure itself and are necessary in each SDDC Region.
- Cloud Management and Service Management applications: vRealize Automation, vRealize Operations, vRealize Log Insight. These components are encapsulated within Virtual PODs.
Rationale
The rationale behind using two or more vCenters is based on the following items:
- Safety: Ensure that excessive operations of a cloud management platform on one of the the Compute vCenter Servers has no negative impact on the Management vCenter Server and thereby the management stack. It is therefore possible to still manage the SDDC itself in such a situation.
- Security: The Cloud Management Platform only needs access to the Compute vCenter Servers and never needs to access the Management vCenter Server. This improves security as even when messing up the Role-Based Access Control (RBAC) within vCenter, the Cloud Management Platform can never accidentally or on purpose harm the applications within the management stack.
- Scale out: Using separate vCenter Server for Compute and Management stack allows us to add additional vCenter Servers within the Compute stack in order to cope with increased payload churn rates. This refers to the case where the number of VM lifecycle operations per unit of time exceeds the capacity of a single vCenter. In these cases the task queue would increase without vCenter ever having a chance to work through them in a reasonable time. To get around this scenario you would add Compute vCenter Server(s) and let the Cloud Management Platform distribute the load across them.
With this an SDDC will usually have a single vCenter Server for the Management Stack and one or more vCenter Server for the Compute Stack within a region.
Virtual Distributed Switches
This design uses three Virtual Distributed Switches (vDS), one for each type of POD. The rationale behind this is that each type of POD has a different kind of network connectivity and therefore needs a separate vDS.
In detail these vDS are:
- Compute vDS: This vDS stretches across all Compute PODs and therefore all Compute clusters.
- Edge vDS: This vDS stretches across the Edge POD and therefore all Edge clusters.
- Management vDS: This vDS stretches across the Management POD and includes the Management cluster.
NSX Transport Zones
Each stack would use a dedicated NSX Transport Zone. The reason for this is that today a 1:1 mapping between NSX Manager and vCenter Server exist. Therefore having 2 separate vCenter Server domains, means that you also end up with two NSX Manager domains. Within each of these domains it is then sufficient to create a single NSX Transport Zone.
vCenter Server to Platform Service Controller Mapping
In this design we use vSphere 6.0, which introduces the Platform Services Controller (PSC). The PSC provides a set of common infrastructure services encompassing Single Sign-On (SSO), Licensing, and Certificate Authority. As a result an administrator could log in to any one of the vCenter Servers attached to PSC within a single SSO domain and manage all resources within these attached vCenters. The result is a single pane of glass from a management perspective.
While an HA deployment scenario does exist for the Platform Services Controller, this scenario is not necessary and not recommended in this design. The High Availability (HA) topology would add additional components with the load balancer and would require additional configuration steps. While this would improve the availability of the PSC itself dramatically, the consumer of the PSC - the vCenter Server - are only able to leverage vSphere HA. As such PSC itself could also use vSphere HA, simplifying the topology.
The resulting design (See Figure 2) would also prepare the overall SDDC design to upcoming capabilities around high availability of the PSC.
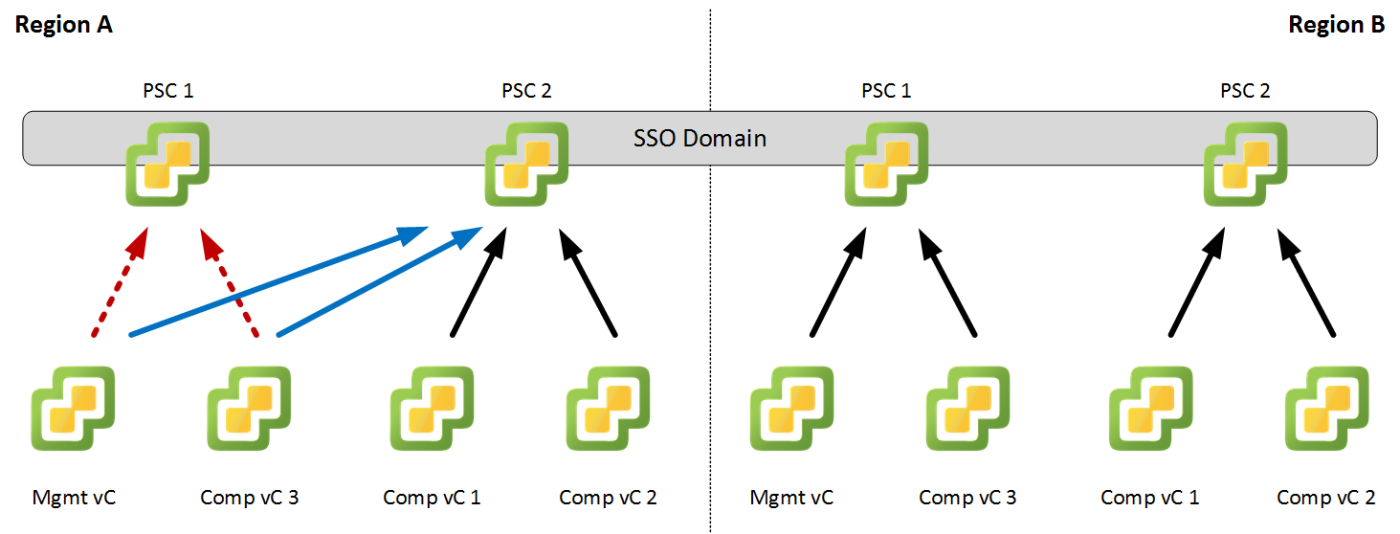
The recommended design is to deploy a pair of Platform Services Controllers per Region and Availability Zones (AZ) and join all PSC in a single Single Sign On (SSO) domain. A maximum of 8 PSC can be placed into a single SSO domain. With this restriction it would be possible to span a single SDDC across up to 2 regions with 2 AZs each.
Within each AZ, the deployed vCenter Server will be split across the available PSC. In the minimum deployment size where you have only one vCenter Server for Management and one vCenter Server for Compute, this would result in a one-to-one mapping.
In the case of a PSC failure, due to an underlying ESXi host failure, the PSC would be restarted via vSphere HA on another ESXi hosts. This would result in a downtime of multiple minutes for the attached vCenter Servers.
In case of a prolonged downtime of a PSC - e.g. due to VM corruption or alike - the vCenter Servers mapped to this PSC (Red arrows in Figure 2) would not be able to leverage this PSC anymore. In this situation the vCenter Servers should be re-pointed to the remaining active PSC within a region (Blue arrows in Figure 2). At this point the SDDC is operational again and the defective PSC can be re-build, for the SDDC to return to a redundant operational state.
Leave a comment