
SDDC Architecture – Regions and Availability Zones (AZs)
Notice: This article is more than 9 years old. It might be outdated.
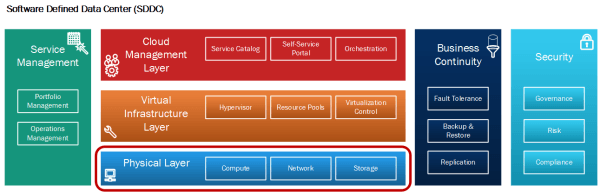
This article is part of a series of articles, focusing on the architecture of an SDDC as well as some of its design elements. In this post we want to look at the physical layer of our SDDC architecture (See Figure 1).
Requirements
A Software Defined Data Center promises to be the new underpinning or platform for delivering today’s and tomorrow’s IT services. As such this next generation infrastructure needs to address some shortcomings of today’s infrastructure in order to be successful:
- Highly automated operation at Scale: Leaner organization that scales sub-linearly with an operating model build around automation. Leverage modular web-scale designs for unhampered scalability.
- Hardware and Software efficiencies: Support on-demand scaling for varying capacity needs. Improved resource pooling to drive increased utilization of resources and reduce cost.
- New and old business needs: Support legacy applications with traditional business continuity and disaster recovery, besides new cloud-native applications.
Physical Layer Design Artifacts
Within the Physical Layer we want to look at these design artifacts in more detail:
- Availability Zones and Regions: Provide continuous availability of the SDDC, minimize unavailability of services and improve SLAs via Availability Zones, while using Regions to improve locality of SDDC resources towards end-users.
Introduction
Availability Zones are a concept to provide continuous availability for the SDDC, minimize unavailability of services and improve service levels. Multiple Availability Zones form a single region.
The core concept behind availability zones is that the likelihood of external factors (power, cooling, physical integrity) affecting an outage in one zone, also leading to an outage in the other zone would be extremely rare (major disasters only) or de-factor impossible. As such deploying workloads (especially management capabilities) across two zones would yield much higher availability and result in improved service levels.
Differentiation
The differentiation between Availability Zones and Regions is very much driven by the physical distance and available bandwidth between two sites. The short distance and high bandwidth between Availability Zones allows the use of synchronous replication between storage arrays deployed across the Zones. The result is the ability to operate workloads across multiple Availability Zones (within the same Region) as if they were part of a single site. This enables designs with very high availability that are suited to host mission critical applications.
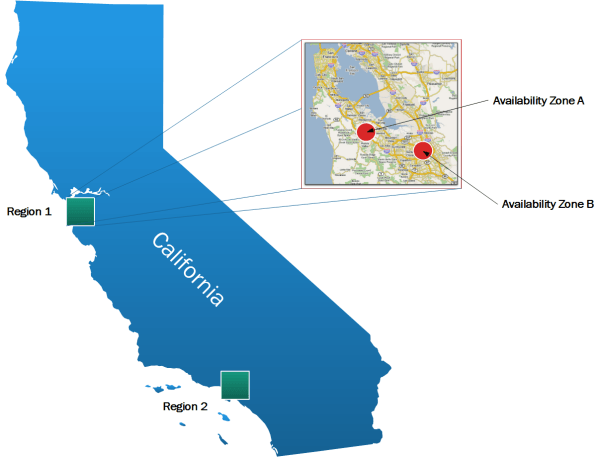
Once the distance between two sites becomes too large, these site can no longer function as two Availability Zones within the same Region and instead need to be treated as separate Regions (See Figure 2).
Availability Zones
Each availability zone (AZ) runs on its own physically distinct, independent infrastructure, and is engineered to be highly reliable. Each zone should have independent power, cooling, network and security. Common points of failures within a physical data center, like generators and cooling equipment, should not be shared across Availability Zones. Additionally, these zones should be physically separate; such that even extremely uncommon disasters such as fires, tornados or flooding would only affect a single Availability Zone. As such Availability Zones are usually either two distinct data centers within metro distance (latency in the single digit range) or two safety/fire sectors (aka data halls) within the same large scale data center.
Multiple Availability Zones (usually two) belong to a single Region, where the physical distance between Availability Zones is below 50 km or 30 mi, therefore offering low single digit latency between Availability Zones, along with large bandwidth - e.g. via dark fiber - between the Zones. This allows the SDDC equipment across the Availability to operate in an active/active manner as a single “Virtual Data Center” or region (See Figure 3).

Regions
The distance between Regions is usually rather large, as having multiple regions caters to a different use case. With multiple regions you can place workloads closer to your customers - e.g. by operating one region on the US East coast along with one region on the US West coast, or operating a Region in Europe and another region is North America. This reduces latency and improves user experience. Regions are also suited to deploy Disaster Recovery (RD) solutions with one Region being the primary site and another Region being the recovery or bunker site.
Last but not least multiple regions can be used to address data privacy laws and restrictions in certain countries and regions, by ensuring that tenant data is kept within a region inside the same country.
Multiple Regions are not suited to be operated as a single virtual data center and rather need to be treated as separate SDDC instances.
Summary
The concept of Availability Zones and Regions is highlighted, which provides a toolset for improving continuous availability of the SDDC, thereby especially catering to the requirement of operating legacy applications with traditional business continuity and disaster recovery needs.
In a nutshell: An availability zone is an “islands” of infrastructure that are isolated enough from each other to stop the propagation of failure or outage across their boundaries. A region brings workloads closer to end-users and serves the purpose of disaster recovery for business continuity.
Leave a comment